2020-05-25-FirstUniqueCharacterInAString
Leetcode-64
1 | Given a string, find the first non-repeating character in it and return it's index. If it doesn't exist, return -1. |
solution
1 | /** |
1 | class Solution { |
1 | Given a string, find the first non-repeating character in it and return it's index. If it doesn't exist, return -1. |
1 | /** |
1 | class Solution { |
监控
prometheus vs zabbix
先对两者的各自特点进行一下对比:
| Zabbix | Prometheus |
|---|---|
| 后端用 C 开发,界面用 PHP 开发,定制化难度很高。 | 后端用 golang 开发,前端是 Grafana,JSON 编辑即可解决。定制化难度较低。 |
| 集群规模上限为 10000 个节点。 | 支持更大的集群规模,速度也更快。 |
| 更适合监控物理机环境。 | 更适合云环境的监控,对 OpenStack,Kubernetes 有更好的集成。 |
| 监控数据存储在关系型数据库内,如 MySQL,很难从现有数据中扩展维度。 | 监控数据存储在基于**时间序列(TSDB)**的数据库内,便于对已有数据进行新的聚合。 |
| 安装简单,zabbix-server 一个软件包中包括了所有的服务端功能。 | 安装相对复杂,监控、告警和界面都分属于不同的组件。 |
| 图形化界面比较成熟,界面上基本上能完成全部的配置操作。 | 界面相对较弱,很多配置需要修改配置文件。 |
| 发展时间更长,对于很多监控场景,都有现成的解决方案。 | 2015 年后开始快速发展,但发展时间较短,成熟度不及 Zabbix。 |
由于最后敲定了Prometheus方案,对于zabbix就云评测了,欢迎指正
Performance?webVitals?以后用到再补充
主要关注性能,pv,redirect,err等问题
阿里云-云监控控制台
可提供网址监控,包括cookie, headers 等自定义的简单配置,进行电话,邮件,短信,旺旺等报警
mod
今天看到Node Current更新了14的版本,看看都有些什么东西
前置了解了一下doc中提到的semver,是一个语义化版本semantic versioning,实现版本和版本规范的解析,计算,比较,用以解决在大型项目中对依赖的版本失去控制的问题,Node.js 的包管理工具 npm 也完全基于 Semantic Versioning 来管理依赖的版本。
参考资料:semver:语义化版本规范在 Node.js 中的实现
sermver弃用一部分功能
在 v13 中,需要调用 --experimental-modules 来开启 ESM module 支持, 而且还会有警告,但目前已经移除警告(还是需要手动开启)
仍在实验中,但是其已经非常完善,移除警告迈向了stable的重要一步
v8不再支持多个ArrayBuffer指向相同的base address
//没看懂
It is expected that there will be an ABI mismatch on ARM between the Node.js binary and native addons. Native addons are only broken if they interact with std::shared_ptr. This is expected to be fixed in a later version of Node.js 14.
Given an array nums of n integers where n > 1, return an array output such that output[i] is equal to the product of all the elements of nums except nums[i].
Example:
1 | Input: [1,2,3,4] |
Constraint: It’s guaranteed that the product of the elements of any prefix or suffix of the array (including the whole array) fits in a 32 bit integer.
Note: Please solve it without division and in O(n).
Follow up:
Could you solve it with constant space complexity? (The output array does not count as extra space for the purpose of space complexity analysis.)
1 | //3ms |
1 | //1ms |
Medium
Given a string containing only three types of characters: ‘(‘, ‘)’ and ‘*’, write a function to check whether this string is valid. We define the validity of a string by these rules:
'(' must have a corresponding right parenthesis ')'.')' must have a corresponding left parenthesis '('.'(' must go before the corresponding right parenthesis ')'.'*' could be treated as a single right parenthesis ')' or a single left parenthesis '(' or an empty string.Example 1:
1 | Input: "()" |
Example 2:
1 | Input: "(*)" |
Example 3:
1 | Input: "(*))" |
Note:
1 | class Solution { |
1 |
|
1 | class Solution { |
1 | class Solution { |
该文档解决:docker下,altermanager收不到prometheus消息
事因,我在一个宿主机下建立了多个docker容器
这些服务之间会有一些互相访问,如prometheus可以发送数据给alertmanager来发送报警信息,alertmanager通过规则处理可以发送邮件,发送钉钉等方式告知用户,问题就出在prometheus的yml配置文档中:
1 | alerting: |
问题出在了prometheus的配置中访问了localhost端口,但这个并不是访问宿主机的9002的端口,而是访问的是docker内部的9002端口
找到问题后,使用了宿主机ip+port的方式进行访问
查询了资料后,发现解决该问题的方法有:
前两种不太推荐,因为如果容器ip更改或者宿主机ip更改就需要更新配置文档,第三种方法不太推荐,run 时候link只是单向的建立连接,第四种docker network create:
1 | //创建网络 |
eventloop使得单线程机制的node实现非阻塞I/O的机制,将任务通过libuv分发给线程池后,交由系统内核完成(多线程),完成后内核通知nodejs,将回调放入poll队列执行
启动nodejs时,eventloop初始化,进程会输入很多script,包括:
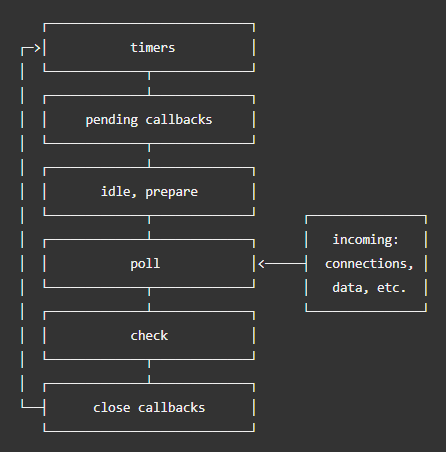
eventloop有六个队列
这些队列被称作phase,每个phase都是一个可以放callback的FIFO队列,当进入一个phase时,队列将执行完phase中的callback或者执行最大数目的callback后将进入另一个phase
设定延迟后,timers会在规定的时间执行,但存在情况延迟,如poll phase执行回调,超过了timer设定的时间。因为poll必须完成一个任务后才可以检查最近的定时器,没到时间就执行下一个callback,执行callback期间无法中断
可以得出结论:
poll控制着定时器何时执行
另外为了防止poll phase 变成恶汉,libuv 制定了一个依赖于系统的硬性最大值,来停止轮询获取更多事件
该队列在系统错误时执行回调(如TCP err),如TCP socket尝试重连收到了ECONNREFUSED,系统需要这些错误报告,那这个错误报告回调就会放在pending callbacks中等待被执行
最重要的阶段,poll主要包含两个功能:
计算阻塞和轮询的IO时间
执行poll 队列里的events
当eventloop进入poll阶段,并没有timers的时候
poll不为空,顺序同步执行任务,直到为空或达到处理数量上限poll为空:如果有setImmediate(),则进入check phase,反之就在poll等客人一但poll为空,eventlopp将会检查计时器是否有快到的,如果有需要执行的,eventloop将要进入timers阶段来顺序执行timer callback
这个phase可以在poll执行完成时开始执行setImmediate()回调。他其实是特殊的定时器队列,使用libuv API在poll完成的阶段执行(这也是他存在的原因)。
socket.desroy()等执行关闭event时候会进入该phase,否则会被process.nextTick()触发
相似却又不同
执行哪个收到上下文的约束,如果两个都被主模块调用,那么进程性能将会收到约束(影响其他app运行)
1 | without IO |
setImmediate()好处在于,如果有IO时会比setTimeout先执行
它是个异步API,并没有出现在六个phase中,他并不属于eventloop的一部分,当操作完成后处理nextTickQueue而不管eventloop执行到哪个阶段,这个异步API依赖于C/C++处理 JavaScript
他的callbakcs会立即执行,直到执行完,eventloop才会正常工作(如果nextTick递归调用则会死循环)
为什么会出现这种设计?
出于所有接口都应该异步的设计思路
1 | function apiCall(arg, callback) { |
代码段会校验参数,如果不正确,它将会把错误传递给回调。该API最近更新,允许传任何参给process.nextTick(),所以你不需要嵌套。仅在剩余代码执行之后我们会把错误反馈给用户,通过nextTick,我们保证apiCal()始终在用户胜于代码之后及eventloop继续之前,执行。为了达到这个目标,JS栈内存允许展开并且立即执行提供的callback,似的nextTick递归不会有报错。
为什么需要process.nextTick()
1 | const server = net.createServer(); |
listen()的callback调用的是setImmiate(),除非传递Hostname,否则立即绑定端口。为了保证eventloop继续,他必须进入poll phase,这意味着,存在可能已经收到了连接,从而允许在侦听事件之前触发连接事件
Given a non-empty, singly linked list with head node head, return a middle node of linked list.
If there are two middle nodes, return the second middle node.
Example 1:
1 | Input: [1,2,3,4,5] |
Example 2:
1 | Input: [1,2,3,4,5,6] |
Note:
1 and 100.题目输出单向链表的中间元素,有这么几个思路
return A[t / 2]第一次提交:0ms
1 | class Solution { |
第二次参考其他代码-提交:
1 | class Solution { |
好久没有刷题了,刚好遇到LeetCode,30天计划,打算强迫自己完成
Given a non-empty array of integers, every element appears twice except for one. Find that single one.
Note:
Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
Example 1:
1 | Input: [2,2,1] |
Example 2:
1 | Input: [4,1,2,1,2] |
思路
以下参考CSDN
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的 Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程
简单说,对 Stream 的使用就是实现一个 filter-map-reduce 过程,产生一个最终结果,或者导致一个副作用(side effect)。
(以下为个人理解)
相对于Java中的Stream流,Java中也有,比如Array.reduce(),Array.foreach()等,通过回调函数的方式进行,
|=:两个二进制对应位都为0时,结果等于0,否则结果等于1;
&=:两个二进制的对应位都为1时,结果为1,否则结果等于0;
^=:两个二进制的对应位相同,结果为0,否则结果为1。
对于这道题来说,[2,2,1]
第零次遍历:init res=0,题目要求找出出现一次的数,所以这个数肯定存在
第一次遍历:res=2
第二次遍历:res=0,因为res^=2(即res=res^2)
第三次遍历:res=1结束遍历
综上:常用^= 以及>>位运算符,C级别的性能
1 | class Solution { |
自己的方法就不贴了。。==感觉好蠢==写了半天。
Given an array nums, write a function to move all 0‘s to the end of it while maintaining the relative order of the non-zero elements.
Example:
1 | Input: [0,1,0,3,12] |
Note:
第一版:
1 | class Solution { |
原本根据题目的意思,想法就是找到一个0,整体往前移动一位,一把梭,但写完发现,本身没有必要整体前移,因为我的判断是num[i]是不是为0,所以只需要将0的个数记录下来,非0的元素前移,最后补0就可以了
第二版
1 | class Solution { |
Say you have an array for which the ith element is the price of a given stock on day i.
Design an algorithm to find the maximum profit. You may complete as many transactions as you like (i.e., buy one and sell one share of the stock multiple times).
Note: You may not engage in multiple transactions at the same time (i.e., you must sell the stock before you buy again).
Example 1:
Input: [7,1,5,3,6,4]
Output: 7
Explanation: Buy on day 2 (price = 1) and sell on day 3 (price = 5), profit = 5-1 = 4.
Then buy on day 4 (price = 3) and sell on day 5 (price = 6), profit = 6-3 = 3.
Example 2:
Input: [1,2,3,4,5]
Output: 4
Explanation: Buy on day 1 (price = 1) and sell on day 5 (price = 5), profit = 5-1 = 4.
Note that you cannot buy on day 1, buy on day 2 and sell them later, as you are
engaging multiple transactions at the same time. You must sell before buying again.
Example 3:
Input: [7,6,4,3,1]
Output: 0
Explanation: In this case, no transaction is done, i.e. max profit = 0.
题目获取最大利润,本以为是通过动态规划DP来做,但是仔细一想,差值就能解决问题
1 | class Solution { |
Write an algorithm to determine if a number is “happy”.
A happy number is a number defined by the following process: Starting with any positive integer, replace the number by the sum of the squares of its digits, and repeat the process until the number equals 1 (where it will stay), or it loops endlessly in a cycle which does not include 1. Those numbers for which this process ends in 1 are happy numbers.
Example:
1 | Input: 19 |
第一版
1 | class Solution { |
其实写完这个框架我就想起来了,可能在计算上存在死循环,就比如
如果这样的题目就进入了死循环,所以干脆直接通过hashset的方式进行过滤
添加了
1 | if(set.contains(sum)){ |
整体代码如下:
Runtime: 5 ms, faster than 9.41% of Java online submissions for Happy Number.
1 | public boolean isHappy(int n) { |
Given n, how many structurally unique BST’s (binary search trees) that store values 1 … n?
Example:
1 | Input: 3 |
题目其实相对比较简单,给出1n,给出能够成的BST的数目,题目一开始的想法是用1n去生成BST,看一下有多少种情况,然后做了很多无用功=.=
越写越不对劲后来查了一下,这道题是有数学规律的
BST有几个特点
所以在i作为根节点时,左子树i-1个节点,右子树n-i个节点
数学的思想在于唯一二叉树的个数为左子树结点的个数乘以右子树的个数。而根节点可以从1到n 中选择,所以有
for(int i=1;i<=n;++i)
sum+=numTrees(i-1)*numTrees(n-i);
再加上边际控制n<=1–>sum=1
就有了解题的代码:
1 | class Solution { |
万幸,自己折腾的生成BST的代码没白写
Given an integer n, generate all structurally unique BST’s (binary search trees) that store values 1 … n.
Example:
1 | Input: 3 |
看题目是前序遍历,我们从上向下查找,外面一层大循环遍历根节点
for(int i=start ;i<=end;i++){}
确定了i节点后可以通过递归写出根节点i的情况下的左右子树
List
leftChild = recursion(start, i - 1); List
rightChild = recursion(i + 1, end);
然后遍历左右子树的每个元素,两层for循环嵌套
for(TreeNode left : leftChild) {
for(TreeNode right : rightChild) {
TreeNode root = new TreeNode(i);
root.left = left;
root.right = right;
res.add(root);
}
}
得到最后的res进行返回,以及处理一下start>end的边际条件就完成了
1 | /** |
问题当时卡在
List
List
当然采用recursion虽然简洁易懂,但两条题目的复杂度都相对较高,是递归的压栈造成的,很多可能相同点的地方可能计算了两遍,导致了两道题目都是打败了5%的solution,当然我们可以通过dp(来自LeetCode)的方式来进行完成
1 | class Solution { |
快速UDP网络连接(Quick UDP Internet Connections,QUIC)
是一种实验性的传输层网络传输协议,由Google开发,在2013年实现。QUIC使用UDP协议,它在两个端点间创建连线,且支持多路复用连线。在设计之初,QUIC希望能够提供等同于SSL/TLS层级的网络安全保护,减少数据传输及创建连线时的延迟时间,双向控制带宽,以避免网络拥塞。Google希望使用这个协议来取代TCP协议,使网页传输速度加快。2018年10月,IETF的HTTP及QUIC工作小组正式将基于QUIC协议的HTTP(HTTP over QUIC)重命名为HTTP/3以为确立下一代规范做准备。
compared with HTTP2+TCP+TLS
0RTT (0次Round-Trip Time,0次往返)建连可以说是 QUIC 相比 HTTP2 最大的性能优势。那什么是 0RTT 建连呢?这里面有两层含义。
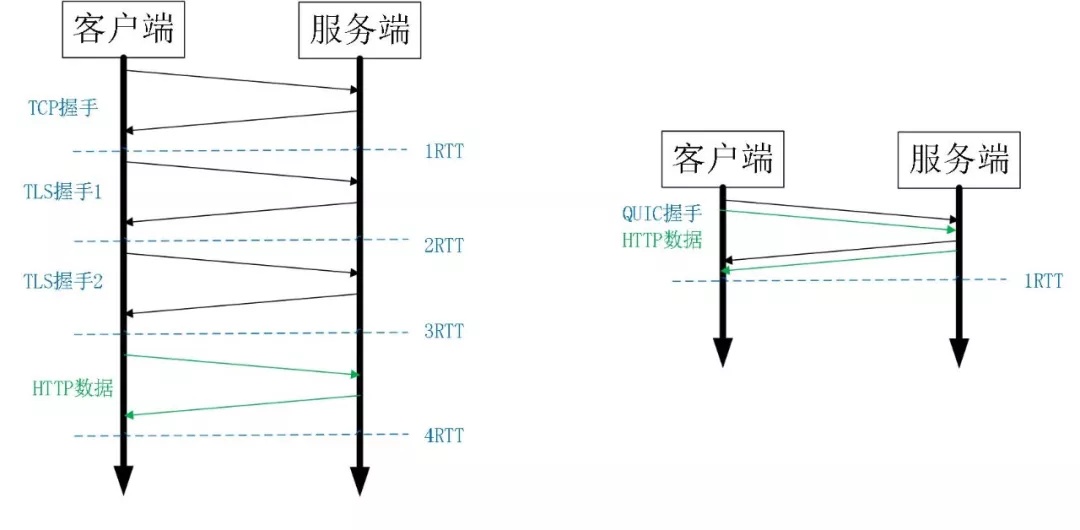
一个完整的 TLS 握手需要两次:
- Client 发送 ClientHello;Server 回复 ServerHello
- Client 回复最终确定的 Key,Finished;Server 回复 Finished
- 握手完毕,Client 发送加密后的 HTTP 请求;Server 回复加密后的 HTTP 响应
TLS Session Resumption
- Client 发送 ClientHello(包含 Session ID);Server 回复 ServerHello 和 Finished
- 握手完毕,Client 发送加密后的 HTTP 请求;Server 回复加密后的 HTTP 响应
TLS 0RTT
0 RTT 是 TLSv1.3 的可选功能。客户端和服务器第一次建立会话时,会生成一个 PSK(pre-shared key)。服务器会用 ticket key 去加密 PSK,作为 Session Ticket 返回。 客户端再次和服务器建立会话时,会先用 PSK 去加密 HTTP 请求,然后把加密后的内容发给服务器。服务器解密 PSK,然后再用 PSK 去解密 HTTP 请求,并加密 HTTP 响应。
HTTPS 握手已经跟 HTTP 请求合并到一起
1.Client 发送 ClientHello(包含 PSK)和加密后的 HTTP 请求;Server 回复 ServerHello 和 Finished 和加密后的 HTTP 响应。
TCP采用了
QUCI默认支持Cubic,另外支持CubicBytes,Reno,RenoBytes,BBR,PCC
可插拔,即灵活生效不需要重启或改变底层
STGW在配置层面进行了优化,针对不同业务,不同网络芝士,不同RTT,使用不同拥塞控制
为了保障TCP的可靠性,使用Seq(sequenceNumber 序号)和ack来确认,N丢失,重传N(问题:N如果重传两次,收到一个ACK,不知道是哪个的ACK)
QUIC使用PacketNumber代替seq,并且packetnumber严格递增,也就是说就算 Packet N 丢失了,重传的 Packet N 的 Packet Number 已经不是 N,而是一个比 N 大的值,另外支持Stream offset更好支持多个packet传输
reneging:TCP通信时,如果发送序列中间某个数据包丢失,TCP会通过重传最后确认的包开始的后续包,这样原先已经正确传输的包也可能重复发送,急剧降低了TCP性能。
为改善这种情况,发展出SACK(Selective Acknowledgment, 选择性确认)技术,使TCP只重新发送丢失的包,不用发送后续所有的包,而且提供相应机制使接收方能告诉发送方哪些数据丢失,哪些数据重发了,哪些数据已经提前收到等
QUIC禁止reneging
TCP 的 Sack 选项能够告诉发送方已经接收到的连续 Segment 的范围,方便发送方进行选择性重传。
由于 TCP 头部最大只有 60 个字节,标准头部占用了 20 字节,所以 Tcp Option 最大长度只有 40 字节,再加上 Tcp Timestamp option 占用了 10 个字节 [25],所以留给 Sack 选项的只有 30 个字节。
每一个 Sack Block 的长度是 8 个,加上 Sack Option 头部 2 个字节,也就意味着 Tcp Sack Option 最大只能提供 3 个 Block。
但是 Quic Ack Frame 可以同时提供 256 个 Ack Block,在丢包率比较高的网络下,更多的 Sack Block 可以提升网络的恢复速度,减少重传量。
收到客户端请求到响应的过程时间成为ack delay,QUIC的RTT需要减掉ack delay(计算我是没看懂。。。)
作用:
tcp承载多个http请求
QUIC 的多路复用和 HTTP2 类似。在一条 QUIC 连接上可以并发发送多个 HTTP 请求 (stream)。但是 QUIC 的多路复用相比 HTTP2 有一个很大的优势。
QUIC 一个连接上的多个 stream 之间没有依赖。这样假如 stream2 丢了一个 udp packet,也只会影响 stream2 的处理。不会影响 stream2 之前及之后的 stream 的处理。
这也就在很大程度上缓解甚至消除了队头阻塞的影响。
HTTP2 在一个 TCP 连接上同时发送 4 个 Stream。其中 Stream1 已经正确到达,并被应用层读取。但是 Stream2 的第三个 tcp segment 丢失了,TCP 为了保证数据的可靠性,需要发送端重传第 3 个 segment 才能通知应用层读取接下去的数据,虽然这个时候 Stream3 和 Stream4 的全部数据已经到达了接收端,但都被阻塞住了。
不仅如此,由于 HTTP2 强制使用 TLS,还存在一个 TLS 协议层面的队头阻塞
Record 是 TLS 协议处理的最小单位,最大不能超过 16K,一些服务器比如 Nginx 默认的大小就是 16K。由于一个 record 必须经过数据一致性校验才能进行加解密,所以一个 16K 的 record,就算丢了一个字节,也会导致已经接收到的 15.99K 数据无法处理,因为它不完整。
那 QUIC 多路复用为什么能避免上述问题呢?
当然,并不是所有的 QUIC 数据都不会受到队头阻塞的影响,比如 QUIC 当前也是使用 Hpack 压缩算法 [10],由于算法的限制,丢失一个头部数据时,可能遇到队头阻塞。
总体来说,QUIC 在传输大量数据时,比如视频,受到队头阻塞的影响很小。
TCP 协议头部没有经过任何加密和认证,所以在传输过程中很容易被中间网络设备篡改,注入和窃听。比如修改序列号、滑动窗口。这些行为有可能是出于性能优化,也有可能是主动攻击。
但是 QUIC 的 packet 可以说是武装到了牙齿。除了个别报文比如 PUBLIC_RESET 和 CHLO,所有报文头部都是经过认证的,报文 Body 都是经过加密的。
这样只要对 QUIC 报文任何修改,接收端都能够及时发现,有效地降低了安全风险。
一条 TCP 连接 [17] 是由四元组标识的(源 IP,源端口,目的 IP,目的端口),当其中任何一个元素发生变化时,这条连接依然维持着,能够保持业务逻辑不中断
比如大家使用手机在 WIFI 和 4G 移动网络切换时,客户端的 IP 肯定会发生变化,需要重新建立和服务端的 TCP 连接。
又比如大家使用公共 NAT 出口时,有些连接竞争时需要重新绑定端口,导致客户端的端口发生变化,同样需要重新建立 TCP 连接。
针对 TCP 的连接变化,MPTCP[5] 其实已经有了解决方案,但是由于 MPTCP 需要操作系统及网络协议栈支持,部署阻力非常大,目前并不适用。
所以从 TCP 连接的角度来讲,这个问题是无解的。
那 QUIC 是如何做到连接迁移呢?很简单,任何一条 QUIC 连接不再以 IP 及端口四元组标识,而是以一个 64 位的随机数作为 ID 来标识,这样就算 IP 或者端口发生变化时,只要 ID 不变,这条连接依然维持着,上层业务逻辑感知不到变化,不会中断,也就不需要重连。
由于这个 ID 是客户端随机产生的,并且长度有 64 位,所以冲突概率非常低。
此外,QUIC 还能实现前向冗余纠错,在重要的包比如握手消息发生丢失时,能够根据冗余信息还原出握手消息。
QUIC 还能实现证书压缩,减少证书传输量,针对包头进行验证等。