(SEMVER-MAJOR)build: update macos deployment target to 10.13 for 14.x (AshCripps) #32454
(SEMVER-MAJOR)doc: update cross compiler machine for Linux armv7 (Richard Lau) #32812
(SEMVER-MAJOR)doc: update Centos/RHEL releases use devtoolset-8 (Richard Lau) #32812
(SEMVER-MAJOR)doc: remove SmartOS from official binaries (Richard Lau) #32812
(SEMVER-MAJOR)win: block running on EOL Windows versions (João Reis) #31954
It is expected that there will be an ABI mismatch on ARM between the Node.js binary and native addons. Native addons are only broken if they interact with std::shared_ptr. This is expected to be fixed in a later version of Node.js 14.
Update to V8 8.1
Others
cli, report: move –report-on-fatalerror to stable (Colin Ihrig)
Given an array nums of n integers where n > 1, return an array output such that output[i] is equal to the product of all the elements of nums except nums[i].
Example:
1 2
Input: [1,2,3,4] Output: [24,12,8,6]
Constraint: It’s guaranteed that the product of the elements of any prefix or suffix of the array (including the whole array) fits in a 32 bit integer.
Note: Please solve it without division and in O(n).
Follow up: Could you solve it with constant space complexity? (The output array does not count as extra space for the purpose of space complexity analysis.)
//3ms class Solution { public int[] productExceptSelf(int[] nums) { int sum =1; int hasZero =0; for(int num :nums){ if(num!=0){ sum*=num; }else{ hasZero++; } }
//1ms class Solution { public int[] productExceptSelf(int[] nums) { int n = nums.length; int[] left = new int[n]; left[0] = 1; for (int i = 1; i < n; i++) { left[i] = left[i-1] * nums[i-1]; } int product = 1; for (int i = n - 1; i >= 0; i--) { left[i] *= product; product *= nums[i]; } return left; } }
Problem-678Valid Parenthesis String
Medium
Given a string containing only three types of characters: ‘(‘, ‘)’ and ‘*’, write a function to check whether this string is valid. We define the validity of a string by these rules:
Any left parenthesis '(' must have a corresponding right parenthesis ')'.
Any right parenthesis ')' must have a corresponding left parenthesis '('.
Left parenthesis '(' must go before the corresponding right parenthesis ')'.
'*' could be treated as a single right parenthesis ')' or a single left parenthesis '(' or an empty string.
Given a non-empty, singly linked list with head node head, return a middle node of linked list.
If there are two middle nodes, return the second middle node.
Example 1:
1 2 3 4 5
Input: [1,2,3,4,5] Output: Node 3 from this list (Serialization: [3,4,5]) The returned node has value 3. (The judge's serialization of this node is [3,4,5]). Note that we returned a ListNode object ans, such that: ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, and ans.next.next.next = NULL.
Example 2:
1 2 3
Input: [1,2,3,4,5,6] Output: Node 4 from this list (Serialization: [4,5,6]) Since the list has two middle nodes with values 3 and 4, we return the second one.
Note:
The number of nodes in the given list will be between 1 and 100.
Say you have an array for which the ith element is the price of a given stock on day i.
Design an algorithm to find the maximum profit. You may complete as many transactions as you like (i.e., buy one and sell one share of the stock multiple times).
Note: You may not engage in multiple transactions at the same time (i.e., you must sell the stock before you buy again).
Example 1:
Input: [7,1,5,3,6,4] Output: 7 Explanation: Buy on day 2 (price = 1) and sell on day 3 (price = 5), profit = 5-1 = 4. Then buy on day 4 (price = 3) and sell on day 5 (price = 6), profit = 6-3 = 3. Example 2:
Input: [1,2,3,4,5] Output: 4 Explanation: Buy on day 1 (price = 1) and sell on day 5 (price = 5), profit = 5-1 = 4. Note that you cannot buy on day 1, buy on day 2 and sell them later, as you are engaging multiple transactions at the same time. You must sell before buying again. Example 3:
Input: [7,6,4,3,1] Output: 0 Explanation: In this case, no transaction is done, i.e. max profit = 0.
key
题目获取最大利润,本以为是通过动态规划DP来做,但是仔细一想,差值就能解决问题
1 2 3 4 5 6 7 8 9 10 11
class Solution { public int maxProfit(int[] prices) { int res = 0; for (int i = 0; i < prices.length - 1; ++i) { if (prices[i] < prices[i + 1]) { res += prices[i + 1] - prices[i]; } } return res; } }
Problem happy Number
Write an algorithm to determine if a number is “happy”.
A happy number is a number defined by the following process: Starting with any positive integer, replace the number by the sum of the squares of its digits, and repeat the process until the number equals 1 (where it will stay), or it loops endlessly in a cycle which does not include 1. Those numbers for which this process ends in 1 are happy numbers.
class Solution { public boolean isHappy(int n) { int sum =0; while (sum != 1) { if(sum!=0){ n=sum;sum=0; } while (n > 0) { int t = n % 10; sum += t * t; n /= 10; } if(sum==0)return false; } return true; } }
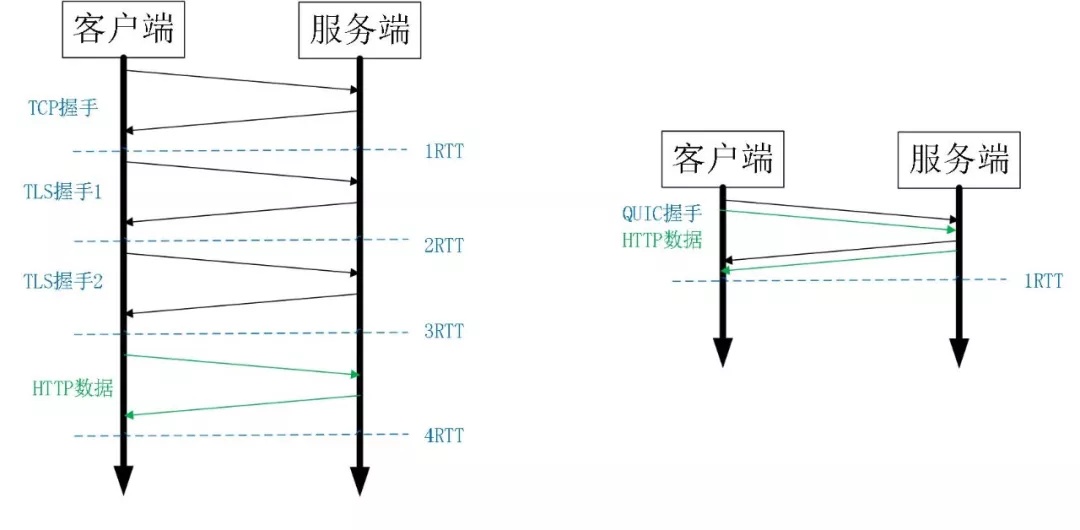
是一种实验性的传输层网络传输协议,由Google开发,在2013年实现。QUIC使用UDP协议,它在两个端点间创建连线,且支持多路复用连线。在设计之初,QUIC希望能够提供等同于SSL/TLS层级的网络安全保护,减少数据传输及创建连线时的延迟时间,双向控制带宽,以避免网络拥塞。Google希望使用这个协议来取代TCP协议,使网页传输速度加快。2018年10月,IETF的HTTP及QUIC工作小组正式将基于QUIC协议的HTTP(HTTP over QUIC)重命名为HTTP/3以为确立下一代规范做准备。